I have uploaded new versions of the HSK 2012/2013 lists, ordered by frequency. There are links to these new lists on the word lists page. This is a pretty good ordering to learn the words in each list; from the most to least frequent. The only change to the frequency odering is when a multi-character word would be learned before the characters within that word - in that case the characters are moved in front of the word.
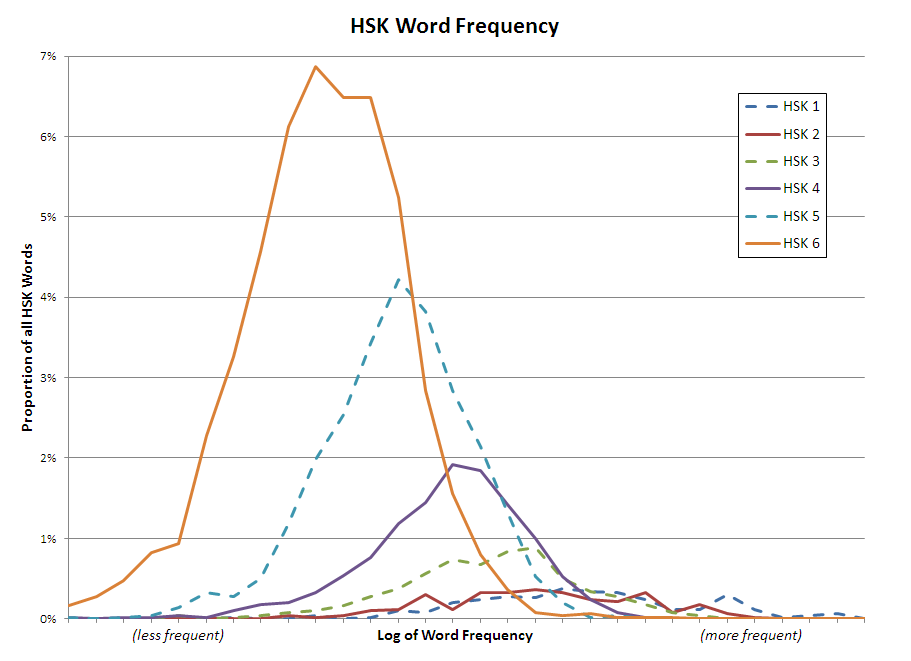
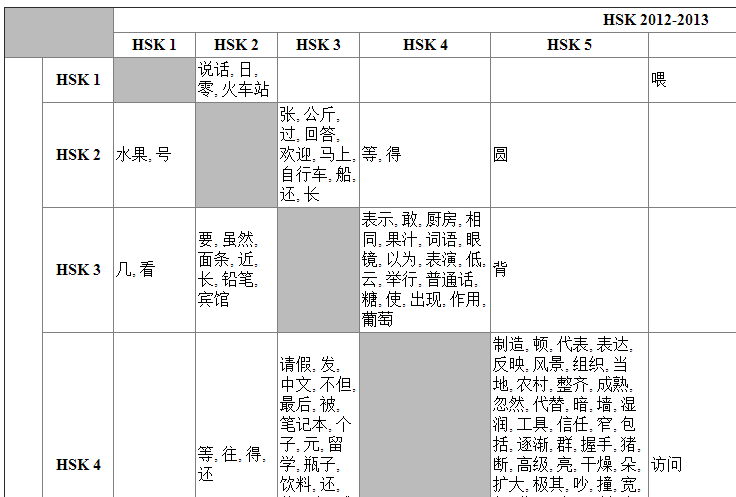 I have added a small script that compares the HSK 2010 and 2012/2013 word lists, to see where the words and characters that were removed from each level ended up. Take a look here: http://hskhsk.pythonanywhere.com/hskwords20102012. If you use Pleco's flashcards to study for the HSK, you should update to the latest words lists. Uploaded to the Word Lists page, and to Pleco's Forums. 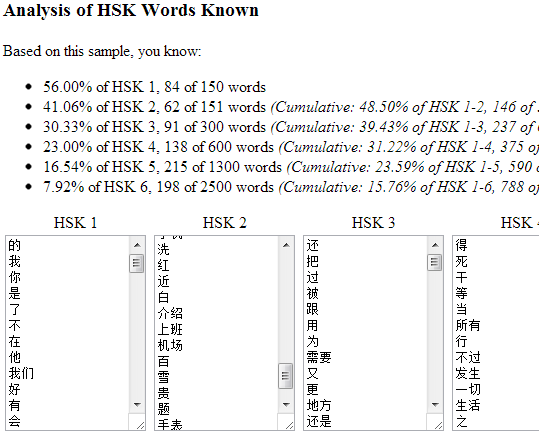 I have put a simple little script online that analyses your Skritter words list, or a similar vocabulary list, or any block of Chinese text, and tells you how many words and characters you know, and which HSK words and characters it contains. It also suggests high frequency words and characters that you are missing. Give it a try here: http://www.hskhsk.com/analyse.html The short answer is "yes, pretty much"! As I showed in an earlier post, the HSK does a pretty good job of covering the majority of common words across all six levels, but it might be interesting to see how early on the really high frequency words are covered. The results aren't too surprising; each HSK level gives you a mix of both high frequency words, and lower frequency (but probably still very useful) words, e.g. the least frequently used word in level 1 is 汉语, although it is quite useful to be able to say the name of the language that you are learning! Nouns such as 北京 and 苹果 have relatively low usage frequency because there are so many of them, but are included in HSK 1 because an early learner's vocabulary wouldn't be much use if all he or she knew was the most common prepositions and verbs. The two graphs below show the exact same data, just presented slightly differently- the second graph stacks the HSK levels on top of each other. They are both histograms, with the 'buckets' on the horizontal axis showing the natural logarithm of the usage frequency of the words at each HSK level. Log frequency is used because word frequency data is very right skewed; a few words are used a lot, and the vast majority are used at very low frequency. The vertical scale shows how many words of that frequency exist at each HSK Level. This graph gives a quick way to visualise all HSK words. Words are coloured by HSK level. More common words are closer to the centre of the graph. You can download a high resolution version from this page.  I have uploaded some HSK 2012 word lists. There are versions with just simplified characters, and others with simplified, traditional, pinyin, and definitions which might be handy for anyone but are specially formatted for use with the iPhone App Hanzi StickyStudy. There is also a list of example sentences that illustrate grammar points, taken from the HSK information published by Hanban. You can download all of the lists here.  This graph shows the percentage of all spoken words that you can expect to understand, against how many words you know, at each Level of the 2012 New HSK. Word frequency data is from SUBTLEX-CH. Of course, being able to understand for example 50% of a block of words will often mean that you still can't understand the meaning at all; for example if you were at HSK level 1 and you were presented with ”一个熊猫", you would understand ”一个" and which means "one of something", but you would have no idea that the thing being talked about is a panda ("熊猫"). There are two lines plotted, an 'optimistic' and a 'pessimistic' estimate. The difference between these two estimates is caused partly by difficulties in defining what constitutes a 'word' in Chinese. The pessimistic estimate is as strict as possible, only counting a word in the frequency list as being known if it explicitly appears in the HSK lists. The optimistic estimate is more permissive, counting a word in the frequency lists as 'known' if all its component characters are part of the HSK word list. As an example, the HSK lists have the words 我们, 你, 他, 她, and 它, but they don't have the words 你们, 他们, 她们, or 它们 which the frequency list does have. Of course, the pattern of adding 们 to pluralise is pretty simple once you have learned it, so it is pointless to for the HSK list to have all of these combinations. The optimistic estimate would count all those -们 words as known, but the pessimistic estimate would count them as not known, so the optimistic estimate is probably better in this example. On the other hand, the HSK lists don't have 美国, which is quite common, although they do use the characters 美 and 国, so the optimistic estimate is probably wrong to count 美国 as known. The true answer would be somewhere between the two estimates, but my feeling is that the 'optimistic' estimate is closer, as so many highly used words in the frequency list are easy to understand combinations of other known words. The Excel file used to generate this graph is available for download here.  I have uploaded a few HSK word and character graphs. See the Graphs Download page for high resolution poster-sized images and graph files that you can use. Most of these images are quite pretty, and some might even be useful to help learners to visualise which words share characters, etc. I am currently using the HSK 1-2 and 1-3 word charts to study for HSK levels 2 and 3. These graphs were generated by a script that I wrote in Python. HSK word lists came from chinesetest.cn. Word frequencies, which were calculated from subtitles, are from SUBTLEX-CH. Character frequencies and composition are from distributed node weight (DNW) data. The graphs were drawn using Gephi and Graphviz. Some pinyin data came from the free Chinese dictionary CC-CEDICT. | AuthorSharing a few resources for fellow Chinese learners. ArchivesJanuary 2014 CategoriesAll |



 RSS Feed
RSS Feed